在短视频创作的浪潮中,你是否渴望拥有独特的视觉效果,让自己的作品脱颖而出?如今,YouTube 带来了令人惊叹的突破 —— 通过知识蒸馏和 PTI 技术,将大模型塞进手机,实现实时 AI 特效,让每个人都能轻松拥有 “千变万化” 的神奇能力。
一、实时 AI 特效:让创作随心所欲
在 YouTube Shorts 相机中,实时 AI 特效带来了前所未有的创作体验。你可以瞬间变身可爱的卡通角色,用夸张的表情和灵动的形象吸引观众的目光;或者在万圣节时,借助 Risen Zombie 特效,将自己变成惊悚的丧尸,为视频增添恐怖氛围。更神奇的是,即使你面无表情,Always Smile 特效也能让你在镜头里时刻挂着灿烂的笑容,仿佛拥有了 “永久微笑” 的超能力。这些特效并非简单的贴图,而是由 AI 根据你的面部特征实时绘制而成,效果自然流畅,真假难辨。
二、大模型 “瘦身术”:知识蒸馏助力移动端应用
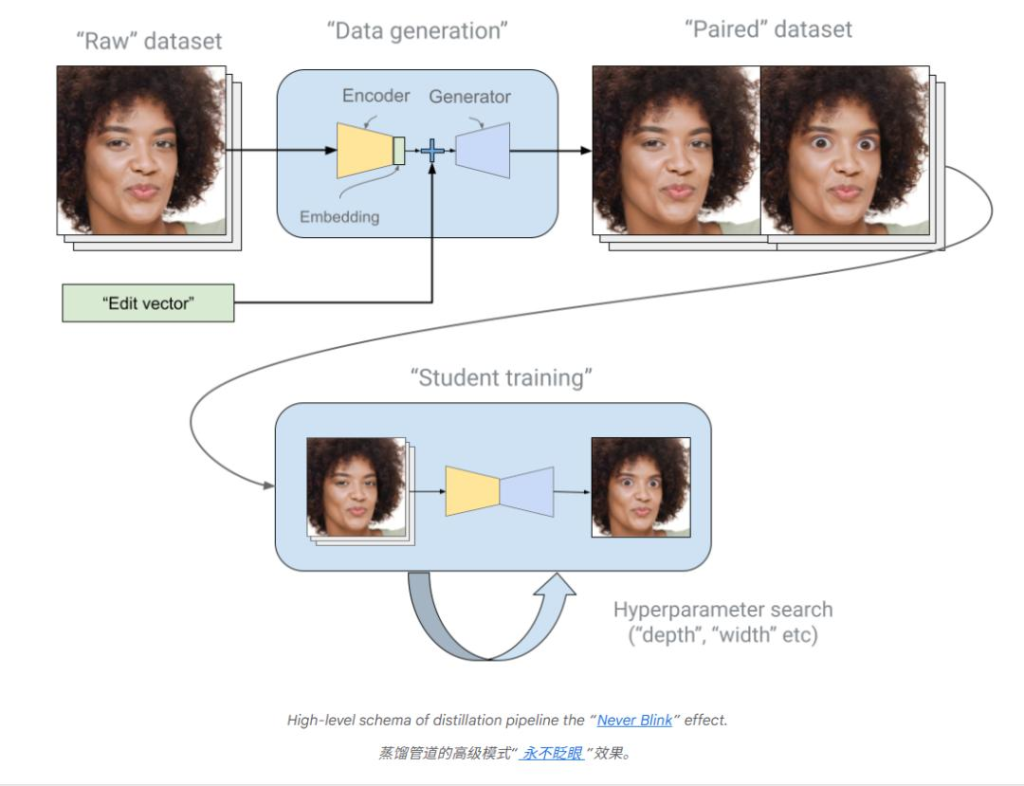
生成式 AI 模型虽然效果惊艳,但体积庞大、运行缓慢,成为了其在移动端应用的阻碍。YouTube 的工程师们通过知识蒸馏这一巧妙方法,成功将庞大的生成模型 “瘦身”。知识蒸馏采用 “老师–学生模式”,大模型作为老师,生成丰富多样的示范样本;小模型则扮演学生的角色,通过不断模仿老师的输出,逐渐学会独立完成任务。大模型如同几十 G 的庞然大物,而小模型则采用轻巧的 UNet+MobileNet 架构,能够在手机 GPU 上轻松达到 30 帧的运行速度。
实际的教学过程并非一蹴而就,工程师们采用迭代式蒸馏,让大模型不断对小模型进行测试和挑战。给人脸戴上眼镜、加上遮挡,模拟各种复杂场景,要求小模型在学习过程中同时满足画面数值匹配、视觉相似、自然不突兀以及兼顾美感等多种标准。这就如同学生反复刷题,不断根据老师的反馈调整参数,优化学习效果。为了让小模型学习得更加高效稳定,工程师们还运用神经架构搜索,自动为小模型筛选最合适的学习内容。经过多轮打磨,小模型终于掌握了大模型的精髓,在 Pixel 8 Pro 上仅需 6 毫秒就能完成一帧运算,iPhone 13 大约 10 毫秒,完全满足实时 30 帧的要求,为手机端实时 AI 特效奠定了基础。
三、PTI 技术:确保特效中的 “你” 还是你
生成式 AI 在制作特效时,常常出现 “inversion problem”,即重新生成的人脸与原始图像存在差异,导致肤色、眼镜等特征丢失,五官变形,让人看起来不像本人。YouTube 引入 Pivotal Tuning Inversion (PTI) 技术来解决这一难题。PTI 技术就像是在加特效前,让 AI 先精准地 “认清你是谁”。原始图像被压缩成潜在向量,生成器依据这个向量绘制出初步的脸,但初始结果往往细节欠佳。此时,工程师让生成器进行反复微调,逐步校正肤色、眼镜和五官等特征,确保身份特征被牢牢固定。随后,再添加风格向量,如笑容、卡通效果或妆容等,最终生成的画面既能展现出独特的特效风格,又能保证还是原本的你,使 AI 特效更像是化妆而非换脸。
四、MediaPipe 加速管道:构建手机端推理流程
训练出轻量级小模型后,如何在手机上稳定运行成为新的挑战。YouTube 借助 Google AI Edge 的开源多模态 ML 框架 MediaPipe,搭建端侧完整推理管道。整个流程主要包括四步:首先,利用 MediaPipe 的 Face Mesh 模块识别视频流中的人脸;接着,由于小模型对人脸位置敏感,系统会对检测到的脸进行稳定裁剪和旋转对齐,保证输入的一致性;然后,将裁剪后的图像转换为张量输入小模型,实时生成特效;最后,把模型输出的人脸图像无缝拼回到原始视频帧中,呈现出连贯自然的最终画面。通过 GPU 加速,Pixel 8 Pro 上的推理延迟被压缩至约 6 毫秒 / 帧,iPhone 13 GPU 约 10.6 毫秒 / 帧,用户打开相机即可体验到流畅的 AI 特效。
五、开启创作新时代:从实时滤镜到视频生成
目前,这套先进的技术已在 YouTube Shorts 全面上线,为创作者们提供了几十种实时特效,极大地丰富了创作手段。不仅如此,YouTube 还在积极探索更多可能性,正在测试的 Veo 模型有望实现从静态图片生成完整视频片段。这意味着,未来创作者只需一张自拍或一幅手绘,就能在手机上轻松生成动态短片,进一步降低创作门槛,让 AI 深度融入创作的每一个环节。从实时滤镜到一键生成短片,YouTube 正引领我们进入一个全新的创作时代,让每个人都能成为创意无限的视频创作者。